IBM's Triplex introduces Trilateralism as a step beyond parallel processing
This information applies paradigm of threes to mainframe clustering technology. It is written from a technical perspective. However, you may look beyond the technical terms for patterns of three. Likely you will see a mainframe computer architecture based on threes theory. Theoretically the Triplex Mainframe cluster is the most advanced, sophisticated and powerful of all commercially available computer architectures. To better understand the internal workings of the Mainframe Parallel TriPlex listed are a variety of technical terms.
1. CPU - Central Processing Unit (primarily a mainframe computer)
2. S/390 - Is another notation for System 390 and represents one IBM mainframe, now called the zSeries.
3. CF - Stands for Coupling Facility. It is used to describe the inter-processor
communication between one mainframe and another in a clustered configuration.
4. Buffer - A device or area used to store data temporarily and deliver it at a rate different from that at which it was received.
5. Cache - A fast storage buffer in the (CPU) central processing unit of a computer. In many cases it is called cache memory.
6. Synchronous - Occurring or existing at the same time.
7. Asynchronous - Lack of temporal concurrence; absence of synchronism.
8. TriPlex - An IBM Parallel Sysplex Cluster that is composed on three processing nodes (three mainframes) demonstrating an application of threes theory.
Mainframe, parallel and clustered systems initially used for numerically intensive operations are now needed in an expanding market space. This is especially true as we move into the era of Big Data. The architectural elements of these systems span a broad spectrum that includes massively parallel processors that focus on incredible performance. To achieve this goal the Triplex contains futuristic multisystem data-sharing technology that allows direct, concurrent read/write access to shared data from all processing nodes in the parallel configuration. This occurs without sacrificing performance, data integrity or compatibility. Each node is able to concurrently cache shared data in local processor memory through hardware-assisted cluster-wide serialization and coherency controls. This in turn enables work requests associated with a single workload (i.e. business transactions or database queries) to be dynamically distributed for parallel execution on nodes in the Triplex cluster based on available processor capacity. Through this futuristic technology the power of three mainframe clustered computers can be harnessed to work in parallel on common workloads, taking the commercial strengths of the mainframe platform to improved levels of competitive price/performance, scaleable growth with continuous availability. It’s true, with the Parallel Triplex down time can be a thing of the past.
Coupling Facility
So how does it work? Specialized hardware provided on each mainframe in the Parallel Triplex Cluster is responsible for controlling communication. This specialized hardware is called a coupling facility. The CF consists of new instructions, high-speed links and link microprocessors. It also uses processor memory to contain local state vectors. These vectors are used to locally track the state of resources maintained in the CF.
The coupling facility provides functions known as command delivery. The coupling support aspect provides the means with programs sending commands to the Triplex to request
locking
caching
queuing
The CF cache structure architecture was designed to support three basic caching protocols:
• Directory-only cache. A directory-only cache utilizes the global buffer coherency tracking mechanisms provided by the CF, but does not store data in the cache structure. This allows read/write sharing of data with local buffer coherency, but refresh of down-level local copies of data items is via access to the shared disk containing the data item, and all updates are written permanently to disk as part of the write operation.
• Store-through cache. When used as a store-through cache, in addition to the global buffer coherency tracking, updated data items are written to the cache structure as well as to shared disk. The directory entries for these data items are marked as unchanged, since the version of the data in the CF matches the version hardened on disk. This enables rapid buffer refresh of down-level local buffer copies from the global CF cache, avoiding I/Os to the shared disk.
•Store-in cache. When used as a store-in cache, the database manager writes updated data items to the CF cache structure synchronous to the commit of the updates. This protocol has additional performance advantages over the previous protocols as it enables fast commit of write operations. However, here the data are written to the cache structure as changed with respect to the disk version of the data. The database manager is responsible for casting out changed data items from the global cache to shared disk as part of a periodic scrubbing operation to free up global cache resources for reclaim. Further, an additional recovery burden is placed on the database manager to recover changed data items from logs in the event of a CF structure failure.
Synchronous, Asynchronous and Vectors
The coupling facility supports both synchronous and asynchronous modes of command delivery. Synchronous commands are completed at the end of the CPU instruction initiating the command, based on highly optimized, low-latency transport protocols. Asynchronous commands are completed after the CPU instruction initiating the command is ended, with the completion notice being sent to the operating system via a new notification mechanism that avoids the necessity of raising a processor interruption.
Secondary command execution. The secondary commands are sent by a CF to the processing node as part of performing certain command operations. A secondary command may store an invalid-buffer indication at a processing node to signal that the node no longer has the latest version of a locally cached data item.
Local state vector control. The coupling facility introduces a set of CPU instructions that interrogate and update local state vectors. A DEFINE VECTOR instruction dynamically allocates, deallocates, or changes the size of a local state vector. The vectors are in protected storage and are only accessible via a coupling facility assigned a unique token. This ensures that programs do not inadvertently overlay vectors for which they have no access authority. Instructions are provided to test and manipulate bits in the state vectors conveying the state of associated resources, and are described in the context of their use.
There are three kinds of local state vectors used:
(1) Local cache vectors are used in conjunction with CF cache structures to track local buffer coherency;.
(2) List-notification vectors are used with CF list structures to provide notification of CF list empty/nonempty state transitions.
(3) List-notification vectors are also employed by the coupling support facility to indicate the completion of asynchronous command operations. Usage scenarios for each of these types of vectors are described later in sections on cache structures, list structures, and command delivery.
Customer Business Objectives
The first key customer business objective was to reduce the total cost of computing for mainframe computer systems. The second objective was to provide a commercial platform that would support the nondisruptive addition of the scalable processing capacity in increments matching the growth of workload requirements for customers, without requiring re-engineering of customer applications or repartitioning of databases and to protect investments customers have in existing applications. A third business objective was to address the increasing customer demands for improved application availability, not only in terms of failure recovery, but for the reduction of planned outage times to logically present a single-system image to users, applications, and the network, and to provide a single point of control to the systems operations staff.
The growing interest in Big Data challenges and Analytics extractions can only find fulfillment with computer systems and computer architectures that are far greater in capacity, throughput and information processing than ever before imagined. Overall corporate computing capacities are grossly inadequate to address the needs of Big Data and Analytics, not to mention that Big Data and Analytics technicians are few and far between. Big Data challenges are now just starting to face large corporations can be anticipated to rapidly accelerate. Paradoxically, the world is so under-computerized that it is staggering. Most large corporations can be anticipated to need somewhere between 10 to 100 times the computing capacity to keep up with the challenges of Big Data and analytics.
But why change and aren’t there pitfalls in migrations to other computer platforms? To address these concerns, Parallel Triplex technology is being introduced compatible with existing applications. Additionally, the benefits of parallel processing are transparently applied to applications through exploitation of subsystems and database managers.
For many years mainframe clustering has been advanced in theory, with no known parallels between one mainframe and another. But today these objectives have been met. This is true by having three mainframes rather than simply two sharing between one another. The Parallel Triplex technology extensions to the S/390 architecture introducing new CPU instructions (channel subsystem technology) are backwardly compatible with the base S/390 architecture and the MVS Operating System. The IBM subsystem transaction managers in the Customer Information Control System (CICS) and the Information Management System Transaction Monitor (IMS-TM), and the key subsystem database managers such as IBM’s Universal Data Base, (DB2) and IMS-DB, which all exploit the data-sharing technology while preserving their existing interfaces. All commercial systems should have a text based interface as a baseline. GUI’s and other interfaces can be added or layered, as analyzed and directed by business need. Why is this? Text based mainframe systems race, whereas GUI based systems perpetually load into cache, grab about a half a dozen Dynamic Link Libraries, and then have numerous other machine steps involved in the process before they present a window. With a Parallel Triplex Cluster it is possible to have information available real time, immediately, at the speed of electricity. A TriPlex Cluster is currently the only computer architecture available that can store data, above the line, in memory 24-7 with no disk I-O’s. Triplex guarantees subsecond response time. Triplex configurations are significantly more powerful than any Personal Computer. That is why mainframes, now and forever, define state-of-the-art for commercial computing applications.
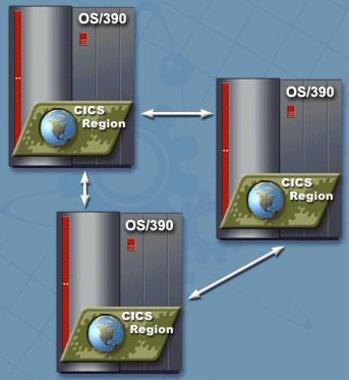
Triplex
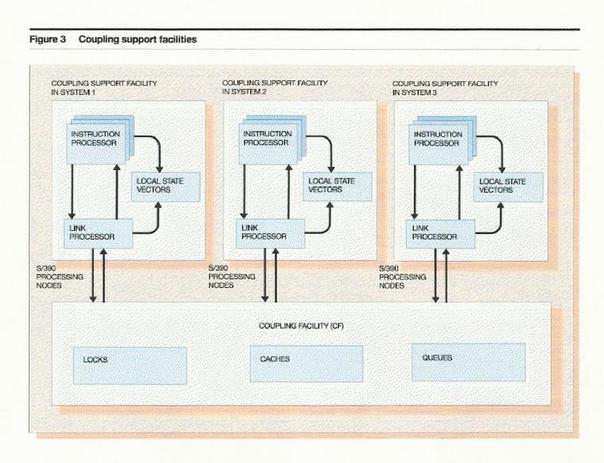
.